Learning long sequences in spiking neural networks
A recent renewed interest in efficient alternatives to Transformers has given rise to state-of-the-art recurrent architectures named state space models (SSMs). This work systematically investigates, for the first time, the intersection of state-of-the-art SSMs with SNNs for long-range sequence modelling. Results suggest that SSM-based SNNs can outperform the Transformer on all tasks of a well-established long-range sequence modelling benchmark. It is also shown that SSM-based SNNs can outperform current state-of-the-art SNNs with fewer parameters on sequential image classification.
Finally, a novel feature mixing layer is introduced, improving SNN accuracy while challenging assumptions about the role of binary activations in SNNs.
This work paves the way for deploying powerful SSM-based architectures, such as large language models, to neuromorphic hardware for energy-efficient long-range sequence modelling.
-
RNNs (Recurrent Neural Networks):
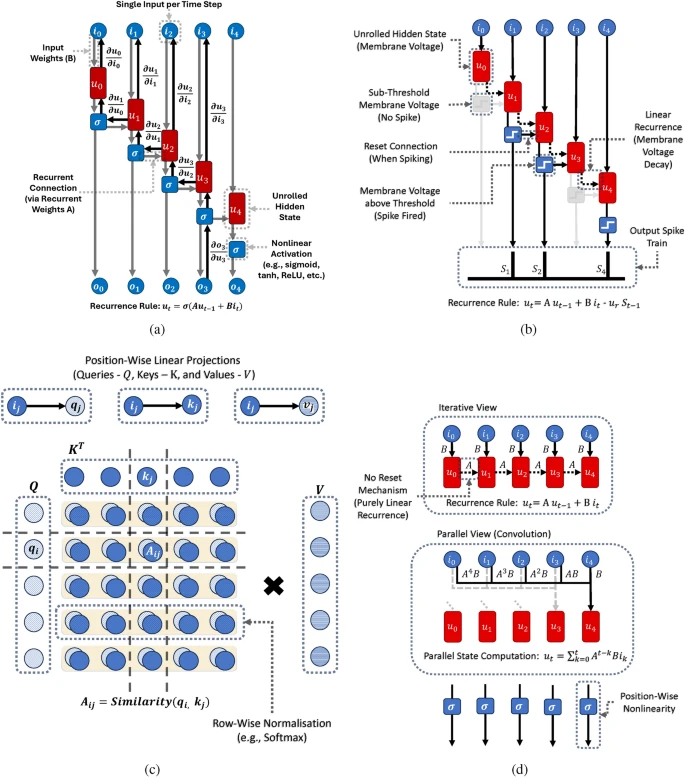
- Think of RNNs like a memory-keeping loop, where each step adds something new to the previous state. They process sequences by evolving the hidden state over time (see how it's unrolled in the diagram).
- Each time step is influenced by a combination of the input and the last hidden state (blue/red arrows in the unrolled computation).
- But they can run into issues: When backpropagating through many time steps (BPTT), things can either fade away (vanishing gradient) or blow up (exploding gradient). It's like when a message in a game of "telephone" becomes too garbled or exaggerated as it passes through.
-
SNNs (Spiking Neural Networks):
- SNNs work kind of like RNNs but with an added twist: neurons only spike when their "membrane voltage" crosses a threshold, creating these sparse, binary spike trains. It's more like real brain activity.
- Also, they introduce a leaky recurrence: the neuron voltage "leaks" over time, and when a spike happens, it gets reset. This keeps it from being as linear as regular RNNs (more organic, like biological processes).
-
Transformers (Self-Attention):
- Transformers are a different beast. Instead of compressing everything into a single evolving state like RNNs, they look at everything at once (all tokens across time).
- Think of it like a big matrix that compares all parts of the input sequence with each other (pair-wise similarities). This is why they’re super powerful, but also less friendly to hardware meant for neuromorphic (brain-like) tasks. They do heavy math (matrix multiplications) instead of iterative steps.
-
SSMs (Structured State Spaces Models):
- SSMs are almost like a hybrid. They can run in parallel but also evolve over time. The key difference here is that they use linear, time-invariant recurrences.
- Each input is projected into a high-dimensional space and then evolved with some transition matrix. So they track how things change over time but can work in parallel, like Transformers.
- It’s like having a grid that stretches across time and space, allowing you to understand how things evolve step by step while also capturing long-term relationships efficiently.
So, in short:
- RNNs and SNNs evolve step-by-step with hidden states, but RNNs can struggle with memory over time, while SNNs mimic brain activity more closely.
- Transformers don’t care about compressing info over time—they look at everything, everywhere, all at once.
- SSMs combine both worlds: they run in parallel while still tracking time, giving more flexibility for long-term tasks without as much overhead.
source: https://www.nature.com/articles/s41598-024-71678-8
tags: #transformers #ai #neural-networks #state-space-models #sequence #spike #spiking-neural-network