Structural Embedding Alignment for Multimodal Large Language Model
Beautiful!
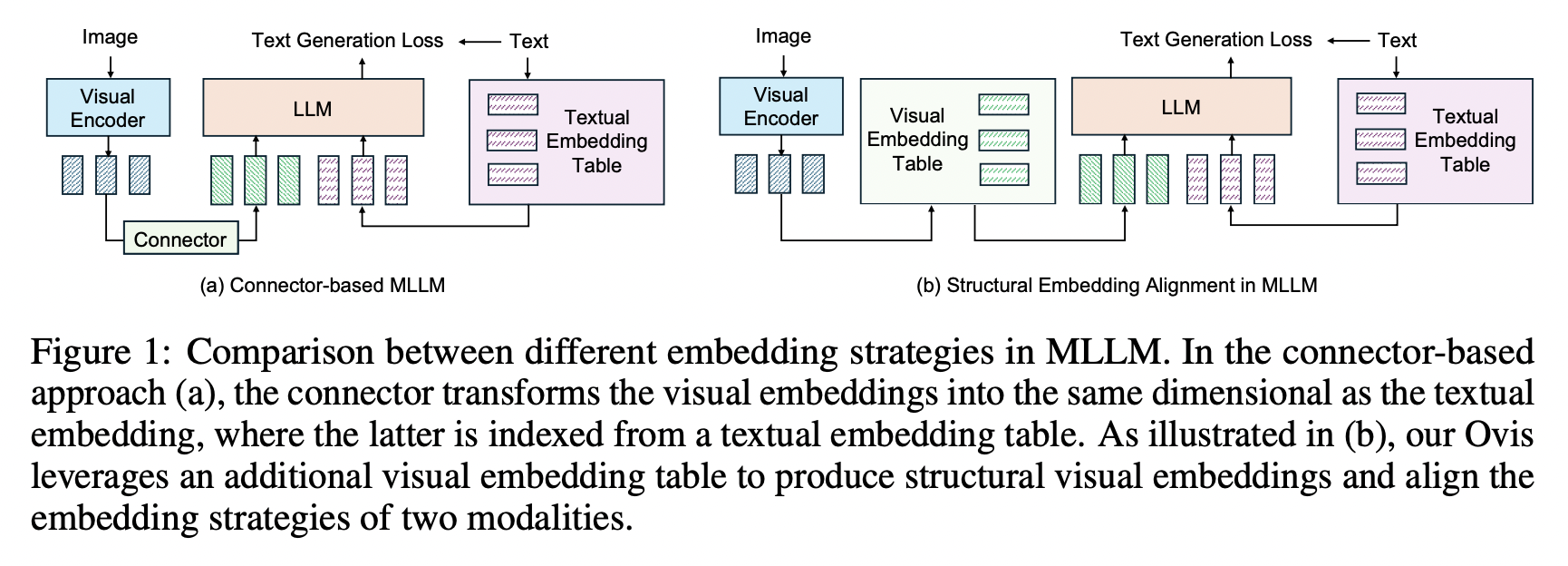
In this work, a team uses visual embeddings and a visual embedding table to process visual information in a more "complete" way to address the misalignment between visual and textual embeddings.
A research team uses a structured visual embedding table to align the information and tackle the problem.
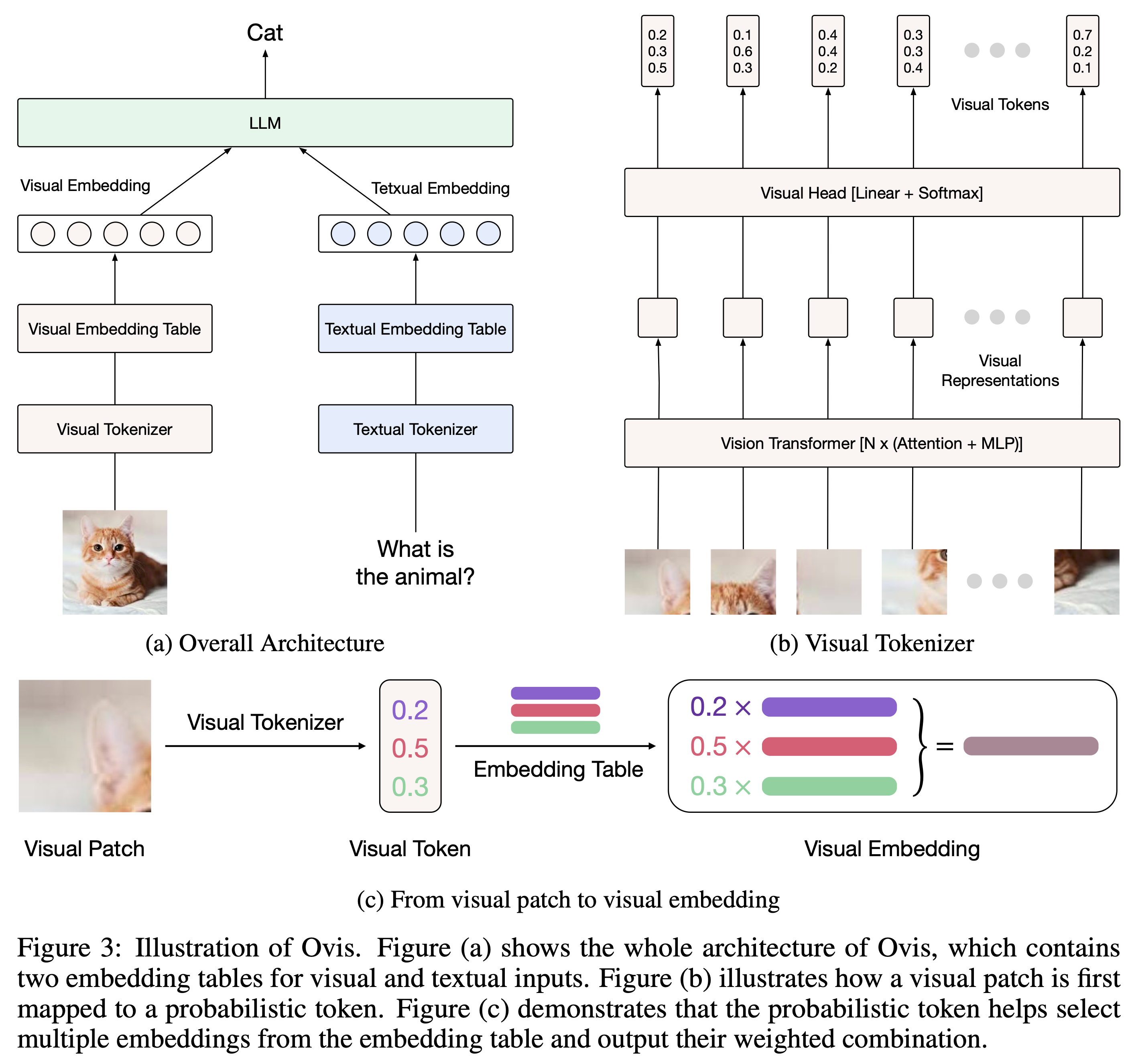
Architecture overview
- Pre-trained vision transformer (ViT) backbone
- LLM ?
- Structured Visual Embedding Table instead of a connector-based approach
Probabilistic Visual Tokens
Both images and texts are input into the MLLM, and they have diverse tokenization strategies.
Given a pre-trained vision transformer (ViT) backbone gθ with parameters θ, we then transform the patches into a sequence of visual representations
For the textual input, let
Instead of using continuous visual tokens in Equation 1, we align the internal tokenization strategies between images and texts to inspire the potential of the MLLM.
To mimic the discrete textual tokens, we use a linear head
Assuming
We set
Visual Embedding Table:
- This is essentially a table or matrix that holds these structured embeddings.
- Each entry in this table corresponds to a visual feature extracted from an image, such as objects, regions, or visual attributes.
- It allows for better visual-textual alignment by structuring the visual features in a way that can be mapped more precisely to text (such as object names or attributes mentioned in a sentence).
In LLMs, it is a common practice to employ a textual embedding table, which maps each word in the vocabulary to an embedding vector. For each textual token
Analogously, we introduce an additional visual embedding table, where each visual word (each row) is associated with an embedding vector
Accordingly, the embedding of each visual token
where
On the other hand, since
which is an expectation of the visual word’s embedding, with the visual word drawn from
demo on HF: https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-9B
source: https://arxiv.org/pdf/2405.20797