Transformer-Based Full-Body Pose Estimation for Rehabilitation via RGB Camera and IMU Fusion
Rehabilitation training plays a vital role in the recovery of lower back and cervical spine function. Human pose estimation can support this process by guiding and evaluating rehabilitation movements. However, specialized rehabilitation exercises often involve severe self-occlusions, posing significant challenges for vision-based pose estimation methods. We thus propose a full-body pose estimation framework tailored for rehabilitation exercises, which fuses monocular images and inertial measurement unit (IMU) signals using a temporal transformer. Multimodal data was collected from six subjects performing 22 specialized rehabilitation movements (e.g., single-leg open book, cross-leg body rotation, standing iliotibial band stretch, standing lumbar extension). The collected data comprises synchronized images, 2D and 3D human keypoint coordinates, and IMU signals.
Our approach first employs a convolutional neural network (CNN) to extract 2D keypoints from image sequences. These keypoints, combined with IMU signals, are then processed by a temporal transformer to estimate 3D joint coordinates.
On the collected data, a vision-only baseline yields a 2D joint position error of 7.33 ± 2.08 pixels and a 3D joint error of 10.05 ± 2.67 cm.
In comparison, the proposed method achieves lower errors, with 5.50 ± 0.75 pixels for 2D joints and 8.27 ± 1.03 cm for 3D joints.
By leveraging inertial data, our method enhances the robustness of pose estimation under challenging conditions such as self-occlusion, demonstrating its potential for both clinical and home-based rehabilitation applications. Index Terms—human pose estimation, rehabilitation exercises, multimodal sensing
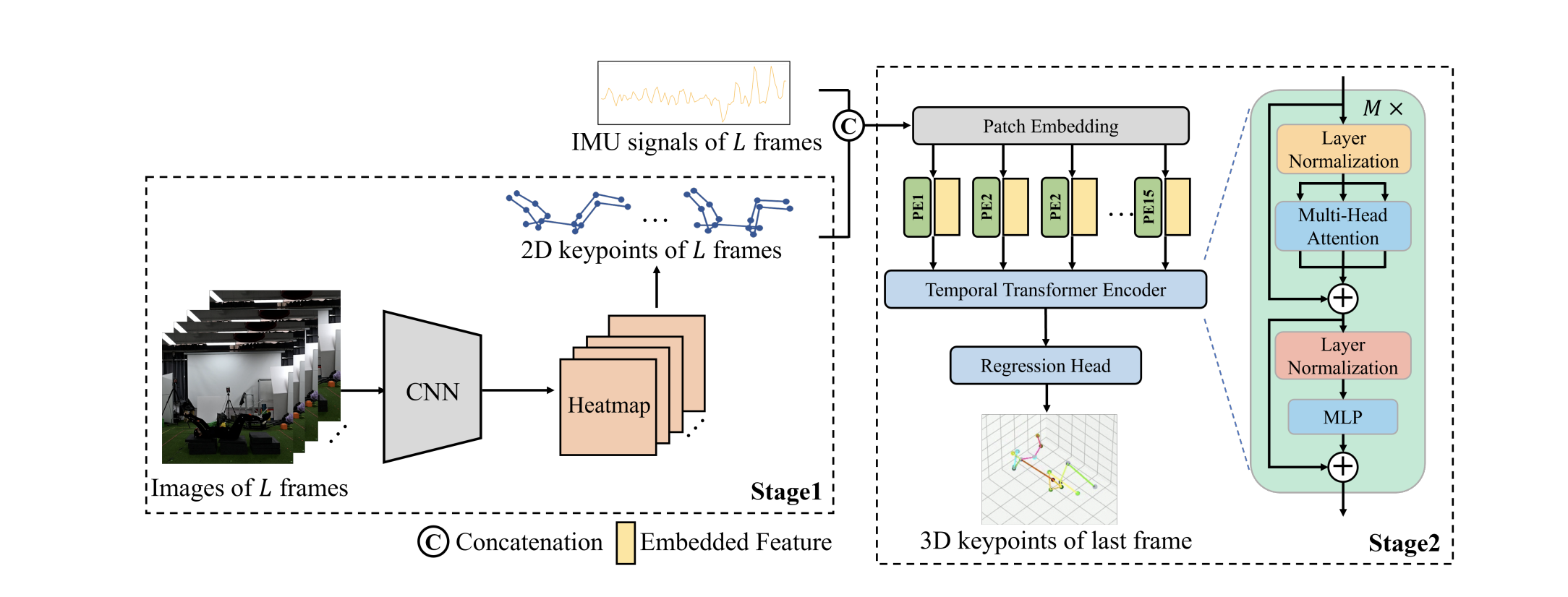
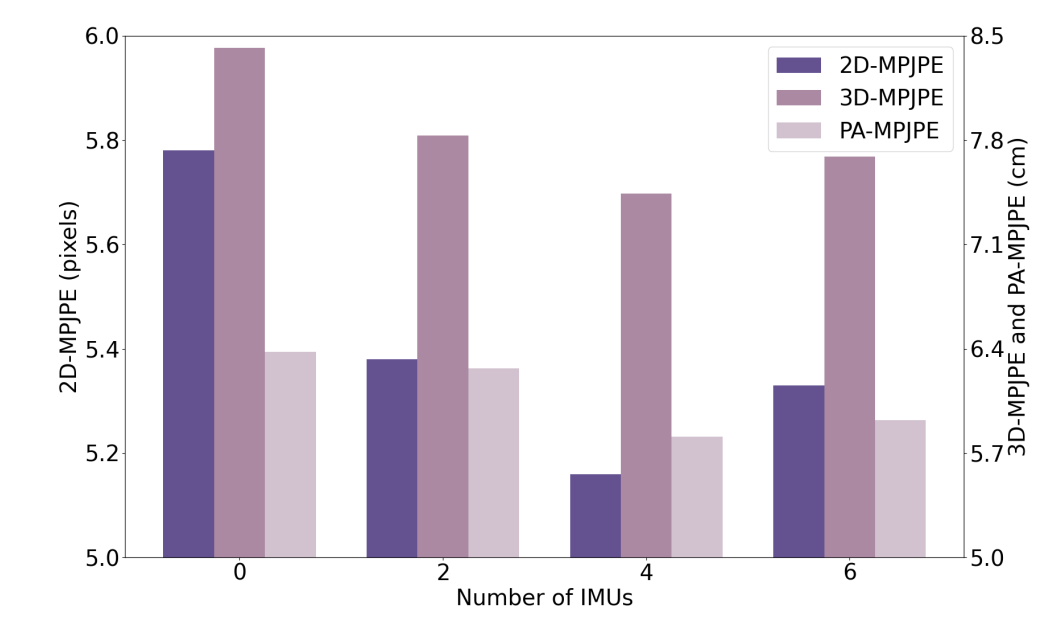
Fig. 3. Ablation study on the impact of input modality on pose estimation performance. The model is trained and tested on the collected rehabilitation motion data using different input modalities: vision only, vision + 2 IMUs, vision + 4 IMUs and vision + 6 IMUs.
DISCUSSION & CONCLUSION
Our ablation study confirms the strong complementary effect of IMU data on visual input, with the fusion of vision and IMU achieving higher accuracy than vision alone. Notably, the combination of vision with four IMUs outperforms that with six. The two additional IMUs, placed on the head and abdomen, contribute less because these regions exhibit limited motion during many rehabilitation exercises, particularly in supine and kneeling postures. As a result, the signals from these sensors may introduce redundancy or noise during model training.
source: https://openreview.net/pdf?id=Ky8gThwpBz
#human-pose-estimation #rehabilitation-exercises #multimodal-sensing #multimodal #sensors #sensing #poseEstimation