How the Brain Distinguishes Music from Speech
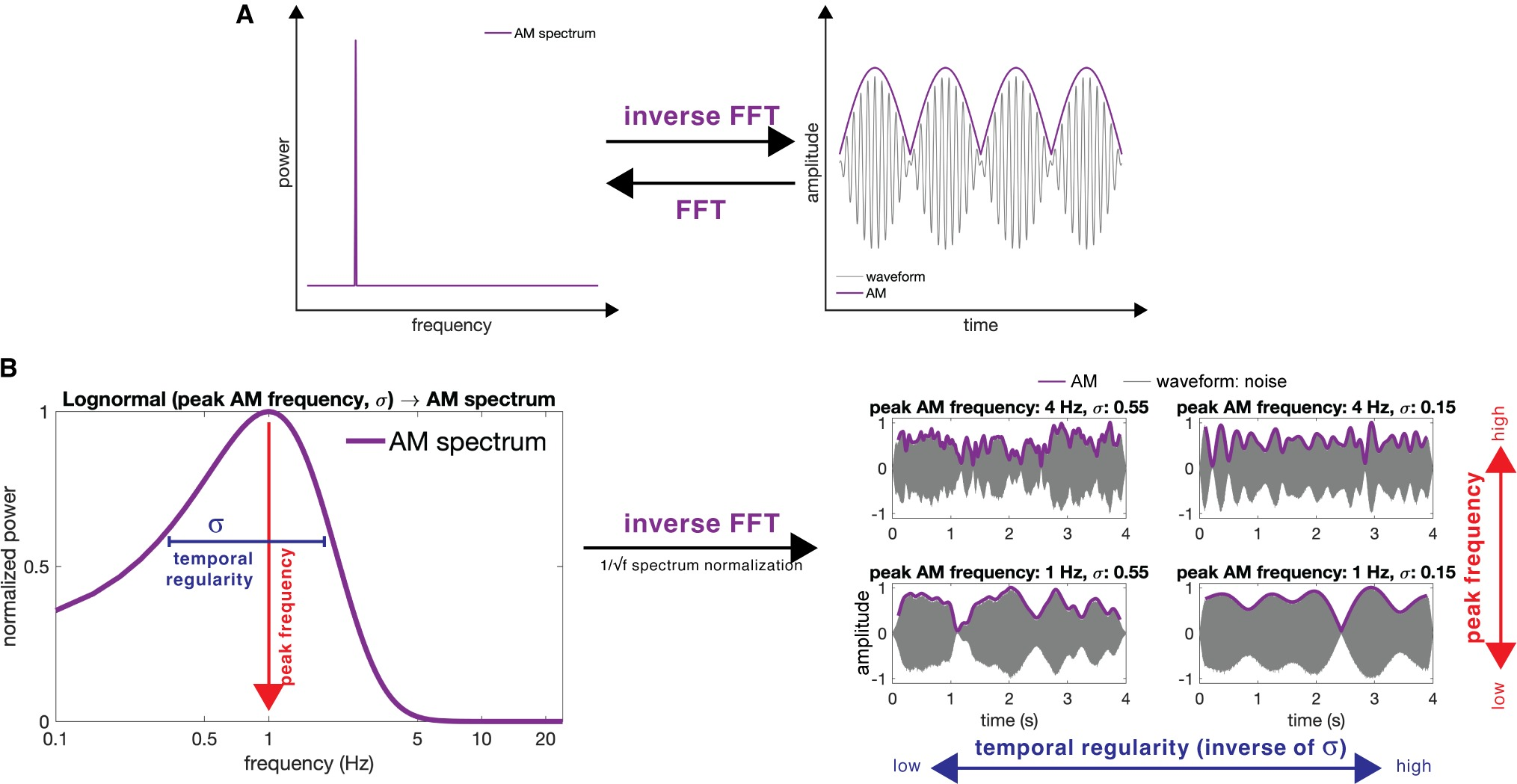
Amplitude modulation
If AM (amplitude modulation) rate and regularity are critical for perceptually distinguishing music and speech, judging artificially noise-synthesized ambiguous audio signals should align with their AM parameters.
Across 4 experiments (N = 335), signals with a higher peak AM frequency tend to be judged as speech, lower as music. Interestingly, this principle is consistently used by all listeners for speech judgments, but only by musically sophisticated listeners for music.
In addition, signals with more regular AM are judged as music over speech, and this feature is more critical for music judgment, regardless of musical sophistication. The data suggest that the auditory system can rely on a low-level acoustic property as basic as AM to distinguish music from speech, a simple principle that provokes both neurophysiological and evolutionary experiments and speculations.
Original study:
The human auditory system uses amplitude modulation to distinguish music from speech
Summary: A new study reveals how our brain distinguishes between music and speech using simple acoustic parameters. Researchers found that slower, steady sounds are perceived as music, while faster, irregular sounds are perceived as speech.
Key Facts:
- Simple Parameters: The brain uses basic acoustic parameters to differentiate music from speech.
- Therapeutic Potential: Findings could improve therapies for language disorders like aphasia.
- Research Details: Study involved over 300 participants listening to synthesized audio clips.
Figures
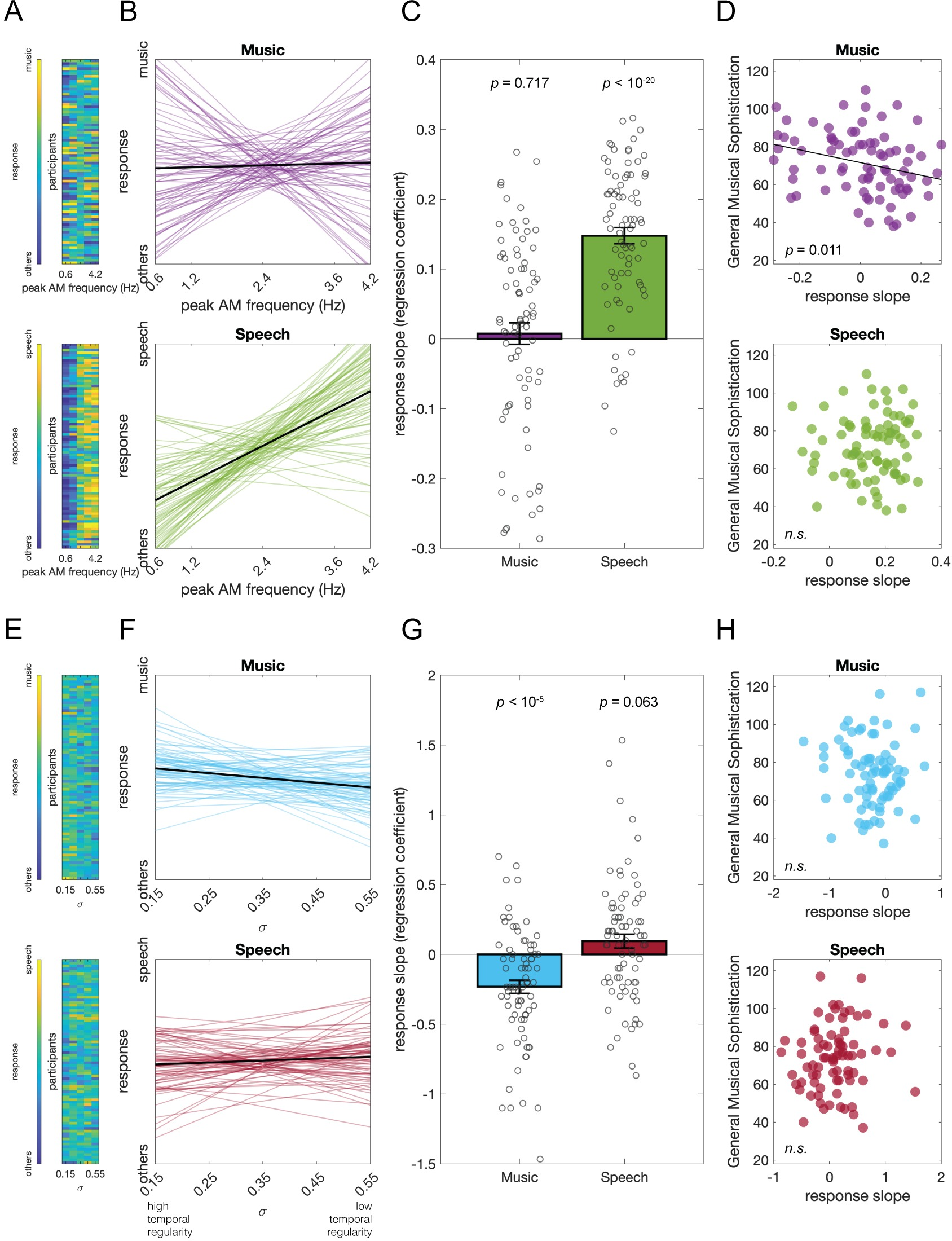

Fig 3. Results of Experiment 2.
(A) The music vs. speech judgment response of each participant at different levels of temporal regularity (σ). (B) Fitted regression lines of each participant’s response. (C) The participants’ response slopes on σ were significantly above 0 for the peak AM frequencies at 1 and 2.5 Hz but not 4 Hz. This suggests that participants tend to judge the temporally more regular stimuli as music and irregular as speech, but this tendency was not observed when the peak frequency was as high as 4 Hz. (D) The response slopes and the General Musical Sophistication scores were not correlated at any peak AM frequencies. Underlying data and scripts are available at https://doi.org/10.17605/OSF.IO/RDTGC and in S1 Data. n.s., nonsignificant.
https://doi.org/10.1371/journal.pbio.3002631.g003
source: https://neurosciencenews.com/music-speech-auditory-processing-27181/
https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3002631
#neuroscience #computational #cognitive #speech #music #rhytms