Reward prediction errors vs. Action prediction error
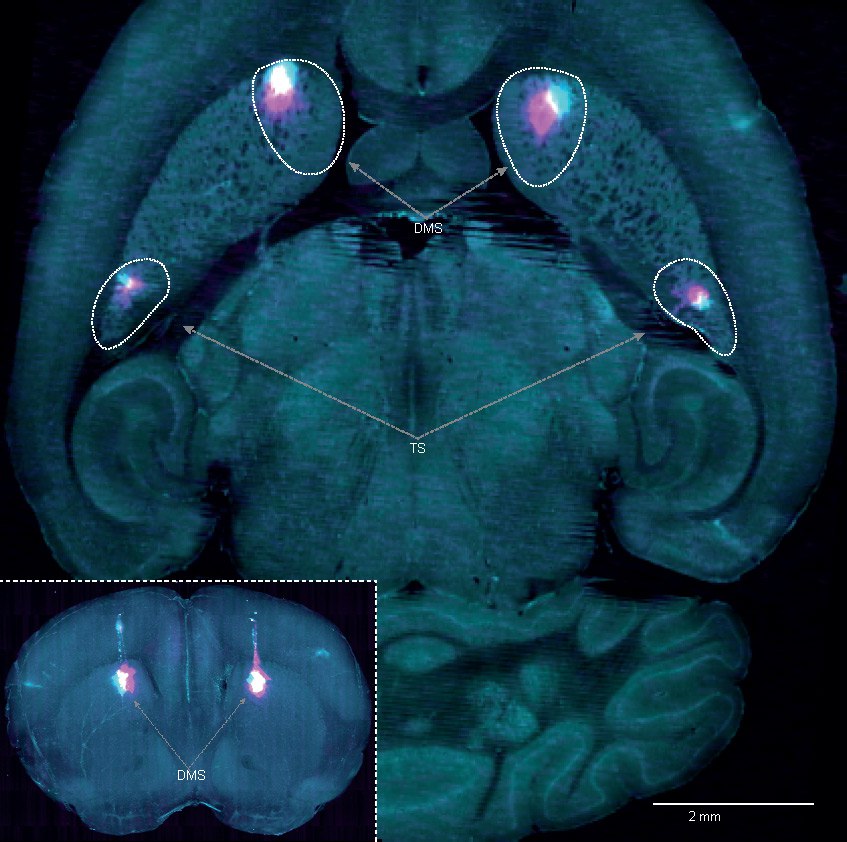
Image shows the two regions of the brain that were inactivated during the task – the dorsomedial striatum (DMS) and the tail of the striatum (TS). Credit: Hernando Martinez Vergara
Discovery of action prediction error
The researchers identified a new type of dopamine signal in the brain that functions differently from the one previously known. Dopamine was already understood to generate reward prediction errors (RPE), which tell the brain whether an outcome is better or worse than expected.
In this study, the scientists discovered a second dopamine signal, called action prediction error (APE), which tracks how often an action is repeated. Together, RPE and APE give animals two distinct ways to learn: by choosing the most rewarding option or by repeating the most frequently chosen one.
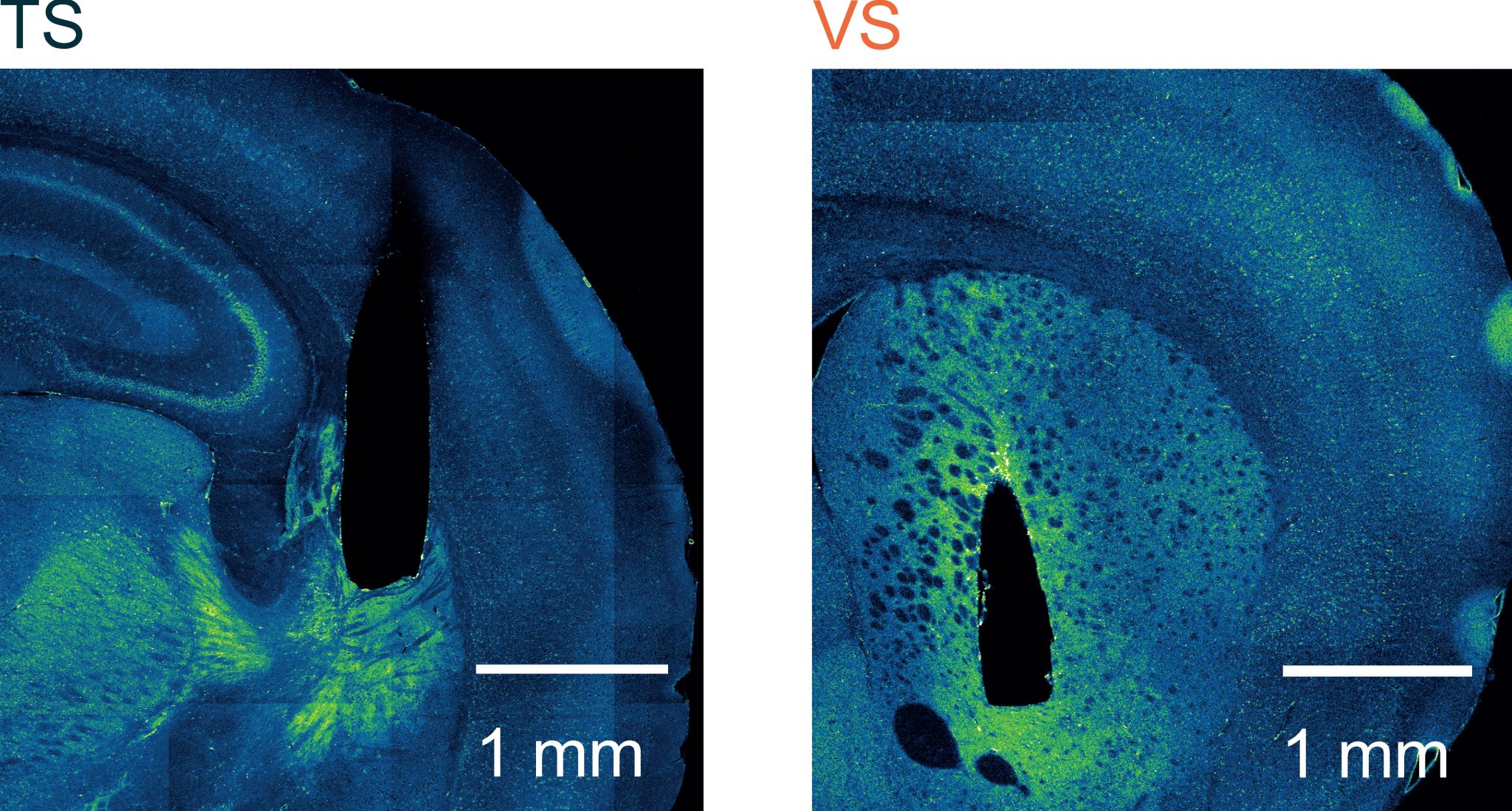
Fluorescent images showing the locations in the brain that the scientists recorded from – the tail of the Striatum (TS) and ventral striatum (VS). Credit: Francesca Greenstreet
“Imagine going to your local sandwich shop. The first time you go, you might take your time choosing a sandwich and, depending on which you pick, you may or may not like it. But if you go back to the shop on many occasions, you no longer spend time wondering which sandwich to select and instead start picking one you like by default. We think it is the APE dopamine signal in the brain that is allowing you to store this default policy,” explained Dr Stephenson-Jones.
Earlier research found that the dopamine neurons involved in learning are located in three parts of the midbrain: the ventral tegmental area, the substantia nigra pars compacta, and the substantia nigra pars lateralis. While some studies showed these neurons play a role in processing reward, previous findings revealed that about half of them are linked to movement—but the purpose of this connection remained unclear.

Flow diagram showing how reward prediction error leads to choosing highest value option and action prediction error leads to choosing most common option. Credit: Sainsbury Wellcome Centre
RPE neurons project to all areas of the striatum apart from one, called the tail of the striatum. Whereas the movement-specific neurons project to all areas apart from the nucleus accumbens. This means that the nucleus accumbens exclusively signals reward, and the tail of the striatum exclusively signals movement.
Dopamine release linked to movement
By investigating the tail of the striatum, the team were able to isolate the movement neurons and discover their function. To test this, the researchers used an auditory discrimination task in mice, which was originally developed by scientists at Cold Spring Harbor Laboratory. Co first authors, Dr Francesca Greenstreet, Dr Hernando Martinez Vergara and Dr Yvonne Johansson, used a genetically encoded dopamine sensor, which showed that dopamine release in this area was not related to reward, but it was related to movement.
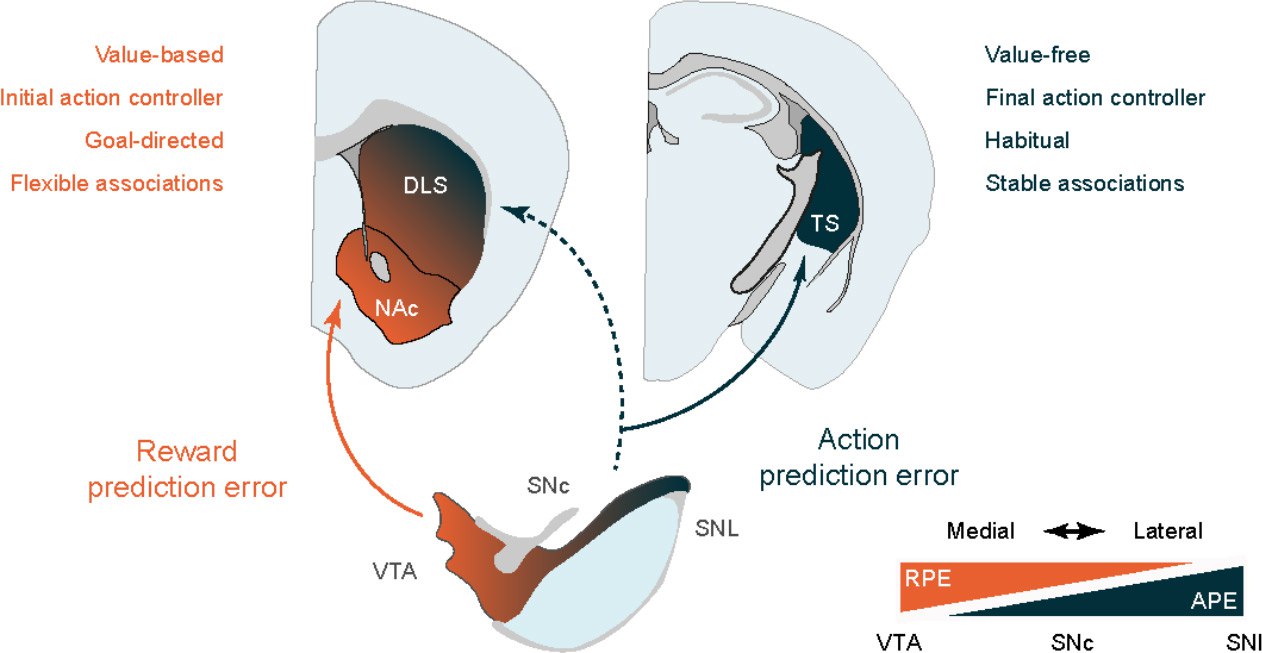
Reward and action prediction error coding dopamine neurons project to distinct areas of the striatum to reinforce different types of associations. Credit: Sainsbury Wellcome Centre
“When we lesioned the tail of the striatum, we found a very characteristic pattern. We observed that lesioned mice and control mice initially learn in the same way, but once they get to about 60-70% performance, i.e. when they develop a preference (for example, for a high tone go left, for a low tone, go right), then the control mice rapidly learn and develop expert performance, whereas the lesioned mice only continue to learn in a linear fashion. This is because the lesioned mice can only use RPE, whereas the control mice have two learning systems, RPE and APE, which contribute to the choice,” explained Dr Stephenson Jones.
APE dominates in late-stage learning
To further understand this, the team silenced the tail of striatum in expert mice and found that this had a catastrophic effect on their performance in the task. This showed that while in early learning animals form a preference using the value-based system based on RPE, in late learning they switch to exclusively use APE in the tail of striatum to store these stable associations and drive their choice. The team also used extensive computational modelling, led by Dr Claudia Clopath, to understand how the two systems, RPE and APE, learn together.
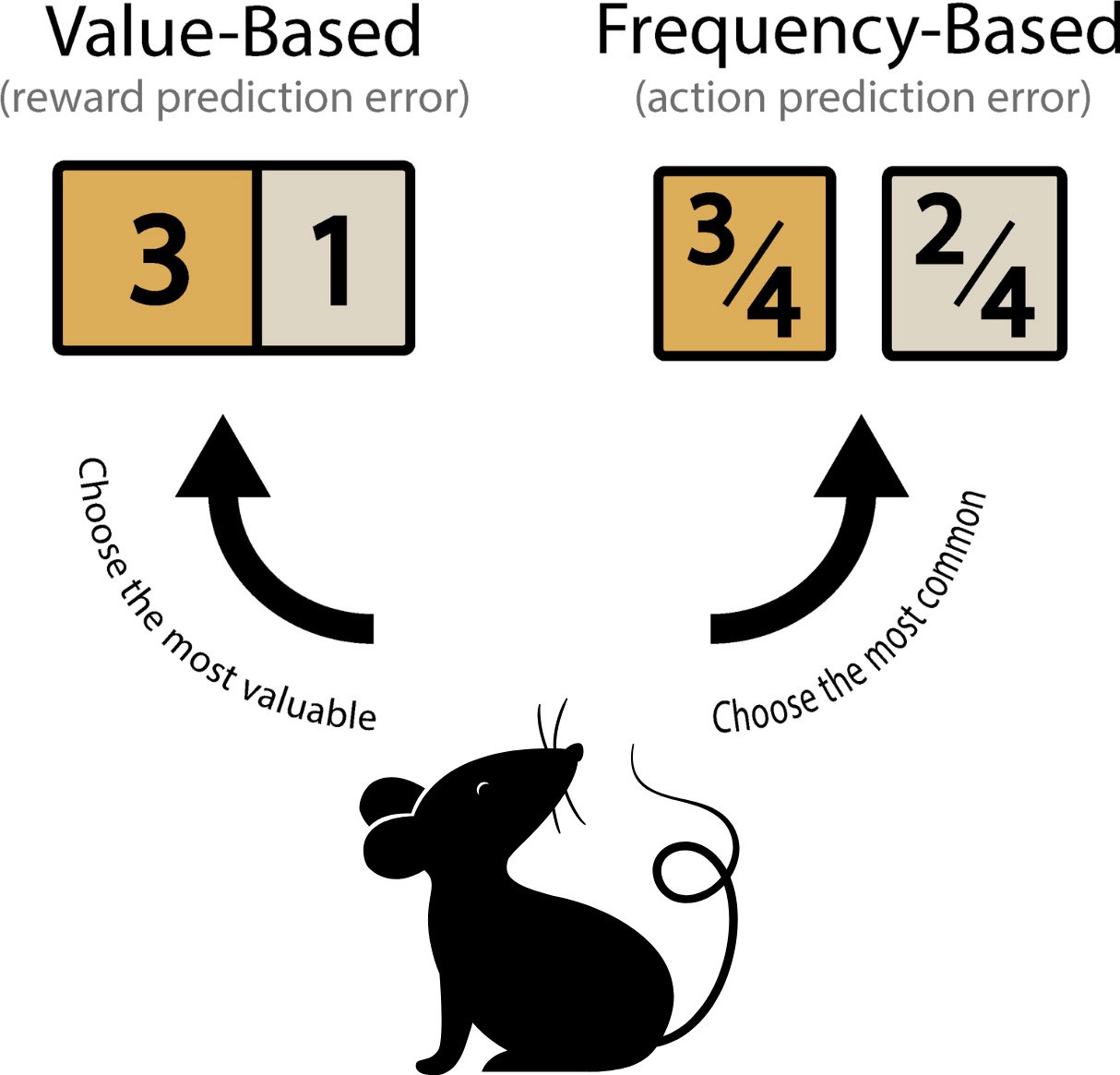
Dual dopaminergic teaching signals are used to learn value-based or frequency-based decision-making strategies. Reward prediction errors are used to update the value of options allowing animals to choose the most valuable option. Action prediction errors are used to update how frequently an option has been chosen allowing animals to choose the most common option. Credit: Sainsbury Wellcome Centre
💡 These findings hint at why it is so hard to break bad habits and why replacing an action with something else may be the best strategy. If you replace an action consistently enough, such as chewing on nicotine gum instead of smoking, the APE system may be able to take over and form a new habit on top of the other one.
source: https://scitechdaily.com/new-research-reveals-the-brain-learns-differently-than-we-thought/
https://www.nature.com/articles/s41586-025-09008-9
#reward #movement #nAC #striatum #dopamine #learning #ReinforcementLearning